All Stories

Leetcode-2140. Solving Questions With Brainpower
Intuition We need to split the binary string s into two non-empty parts—left and right—so that the score, defined as “number of zeros in the left part” plus “number of...

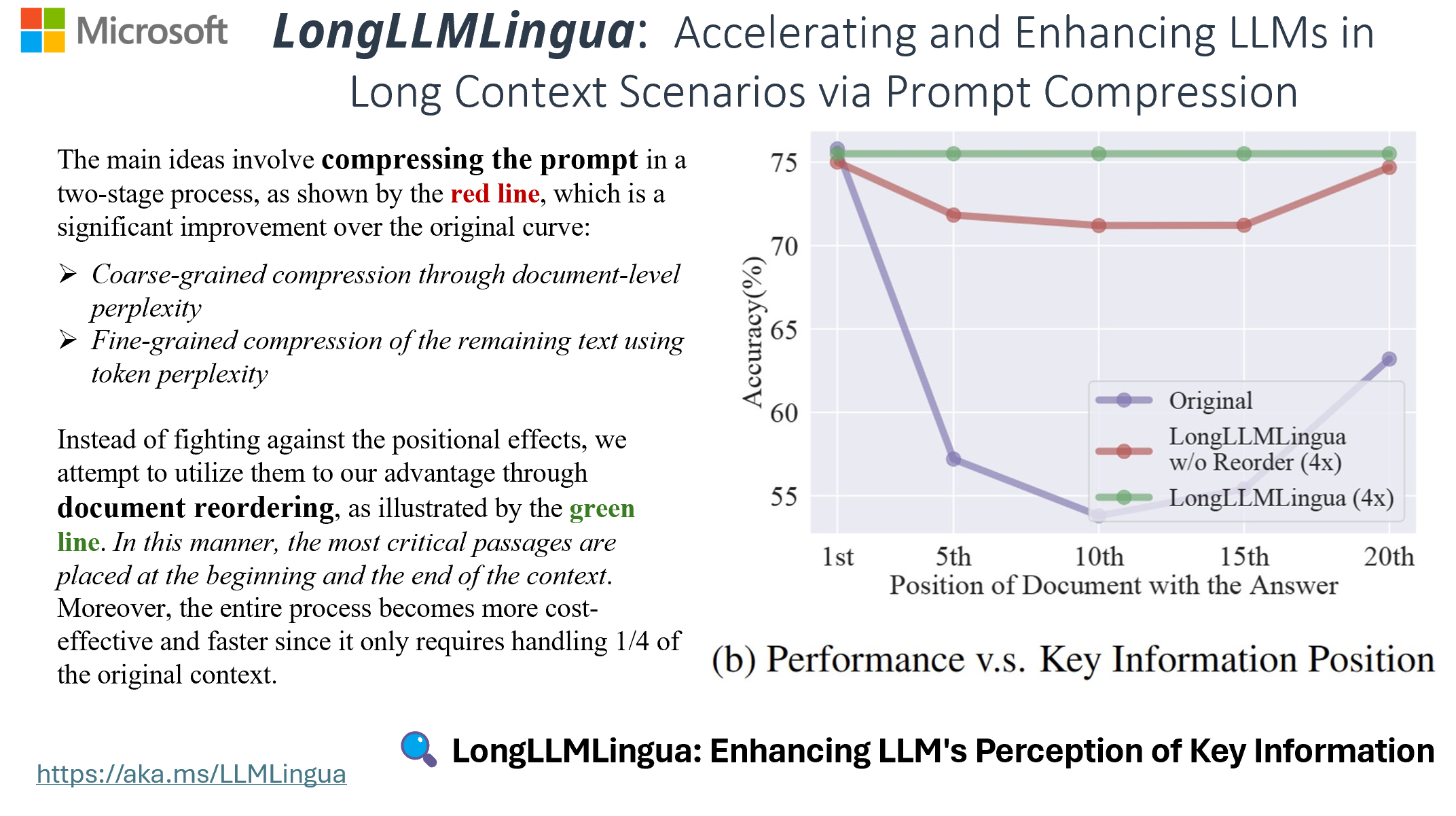
LongLLMLingua Model: A Solution for LLMs in Long Context Scenarios
Core Challenges 1. Question-Context Relevance Problem Traditional prompt compression methods face several critical issues when dealing with long contexts: Traditional Approach: Input: [Document1, Document2, ..., DocumentN] + Question Process: Compress...
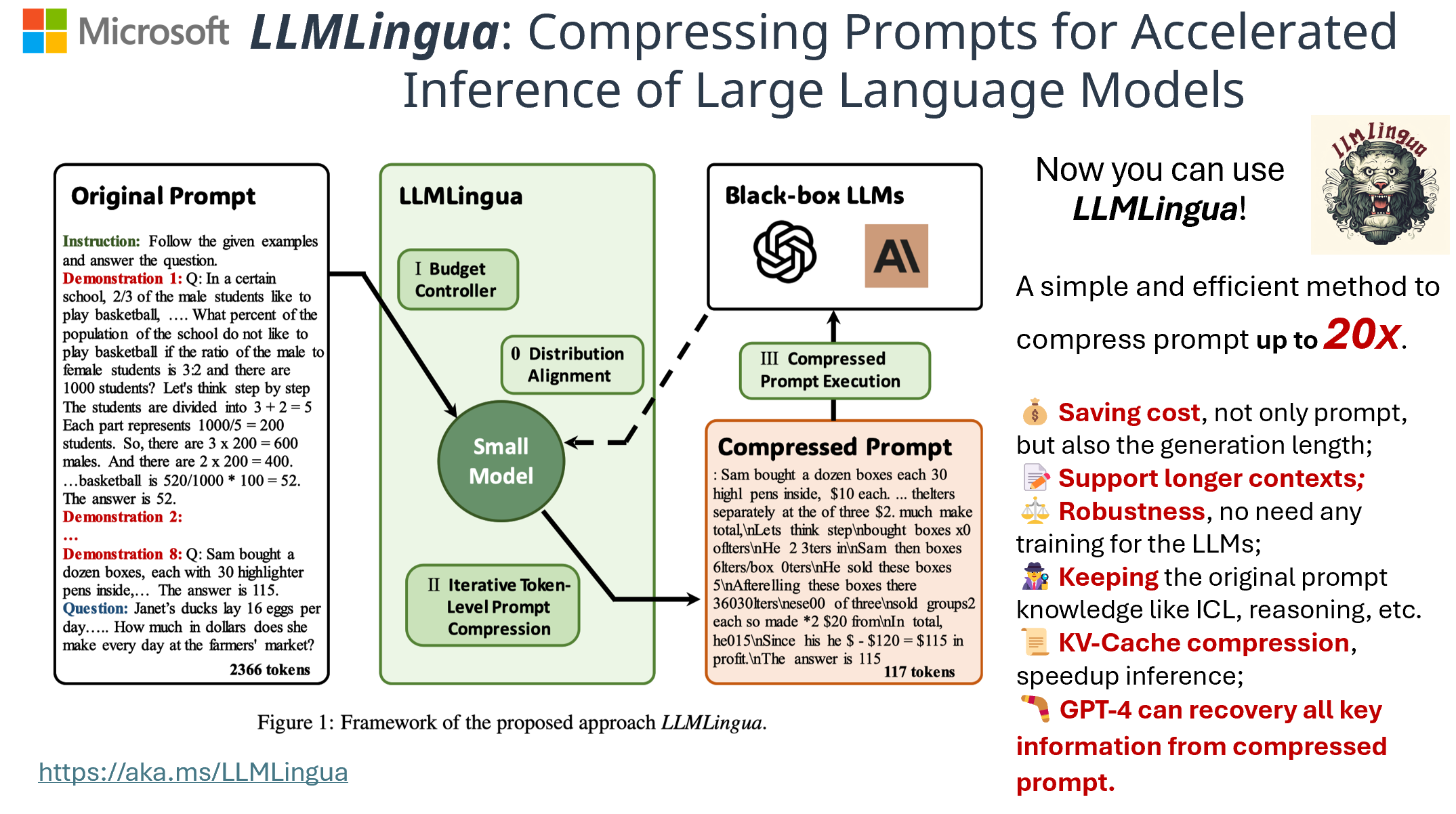
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
The Challenges of of LLMs Large language models (LLMs) have revolutionized various applications due to their remarkable capabilities. Advancements in techniques like chain-of-thought prompting and in-context learning have significantly enhanced...
LLaMA: Open and Efficient Foundation Language Models
Exploring the Architecture, Training Data, and Training Process of LLaMA The sources provide a detailed explanation of the LLaMA model, covering its architecture, the data it was trained on, and...
Understanding Anchor Boxes in Object Detection
Anchor boxes play a crucial role in overcoming the limitation of traditional object detection approaches, where each grid cell can detect only one object. By allowing multiple objects to be...