
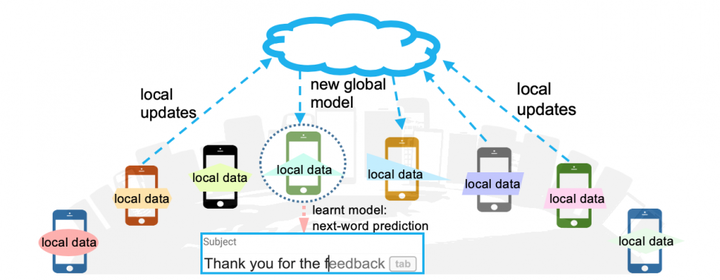
There was a paper, Communication-Efficient Learning of Deep Networks from Decentralized Data by Google (3637 citations!!!), in which the authors had proposed a federated optimization algorithm called FedAvg and compared it with a naive baseline, FedSGD.
FedSGD
Stochastic Gradient Descent (SGD) had shown great results in deep learning. So, as a baseline, the researchers decided to base the Federated Learning training algorithm on SGD as well. SGD can be applied naively to the federated optimization problem, where a single batch gradient calculation (say on a randomly selected client) is done per round of communication.
The paper showed that this approach is computationally efficient, but requires very large numbers of rounds of training to produce good models.
Before we get into the maths, I’ll define a few terms -