
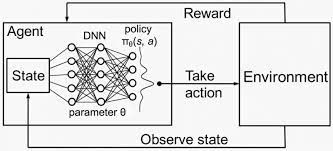
Why DQN?
- in an enviroment with a continue state space, it is impossible to go through all the possible states and actions repeatedly, since there are an infinite number of them and the Q-table would be too big.
- DQN solves this problem by approximating the Q-function thourgh a Neural Network and learning from the previous traning experiences, so that the agent can learn more times from experience already lived without the need to live them again, as well as avoiding the excesive computational cost calculating and updating the Q-table for continous state spaces.
Component
- Main Neural network: The main NN tries to predict the expected return of taking each action for the given state. Train and update every episode.
- Replay Buffer: The replay buffer is a list that is filled with the experiences lived by the agent. An experience is represented by the current state, theaction taken in the current state, the reward obtaind after taking that action, whether is it a terminal state or not, and the next state reached after taking the action.
- State size
- Action size
- Gamme
- Episode
- Number of steps
- Epsilon value, epsilon decay
- Learning rate
- Target NN update rate
Source Code
- https://github.com/danghoangnhan/DQN
References
- https://www.youtube.com/watch?v=97gDXdA7kVc&t=232s
- https://pytorch.org/tutorials/intermediate/reinforcement_q_learning